
Google Cloud attempts to make data ‘limitless’ with BigLake and new data cloud alliance
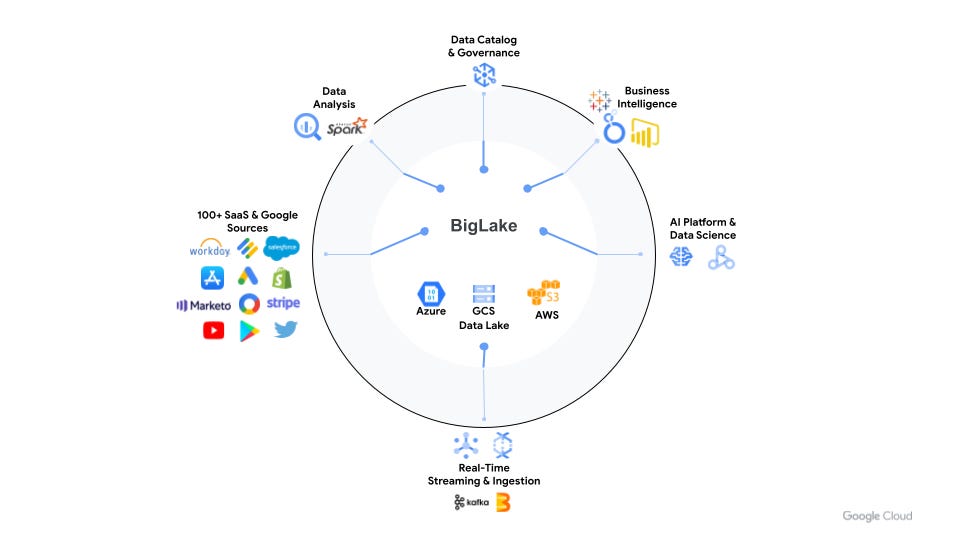
Image: Google
Google Cloud has announced the preview of its data lake storage engine, BigLake, as part of its aim to remove all “limits of data” as well as break the barrier between data lakes and warehouses.
As Google Cloud data analytics product manager Sudhir Hasbe explained, BigLake has been designed to provide a unified interface across any storage layer, including data lake and data warehouse, no matter the format.
“It’s so you don’t have to copy the data, move the data across your object stores, like in Google Cloud Storage, S3, or Azure in a multi-cloud environment, and you get a single place to access all of your data,” he told media during a pre-briefing.
Hasbe added BigLake can support all open file formats such Parquet, along with open source-processing engines like Apache Spark or Beam, and various table formats including Delta and Iceberg.
“It’s completely open,” he said.
“We’re taking innovation from Google, extending it to the open-source world and making it more open for all of our customers.”
BigLake is set to become central to all of Google Clouds’ investments going forward.
“We will make sure all the various tools and components work seamlessly with BigLake going forward,” Hasbe said.
Additionally, Google announced the establishment of a Data Cloud Alliance which has been formed alongside other founding partners including Confluent, Databricks, Dataiku, Deloitte, Elastic, Fivetran, MongoDB, Neo4j, Redis, and Starburst.
Under the alliance, the members will provide infrastructure, APIs, and integration support to ensure data portability and accessibility between multiple platforms and products across multiple environments. They will also collaborate on new, common industry data models, processes, and platform integrations to increase data portability.
“We have committed ourselves to remove the barriers to lock in data. We have committed ourselves to make sure the data can be accessed and processed across products, and we have committed ourselves to put the customer at the centre of our joint innovation,” Google Databases, Data Analytics, Looker general manager Gerrit Kazmaier claimed.
As part of its Data Cloud Summit, the tech giant also introduced Vertex AI Workbench to bring data and ML systems into a single interface, so teams can have common tools sets across data analytics, data science, and machine learning. It has been designed to be directly integrated with a full suite of AI and data products, including BigQuery, Serverless Spark, and Dataproc.
“This capability allows teams to build, train, and deploy ML models in a simple notebook environment that can enhance and make it five times faster than other tools they might use,” Google Cloud AI senior product manager Harry Tappen said.
The company also announced Vertex AI Model Registry. Currently in preview, the Model Registery has been designed to be a “central repository for discovering, using, and governing machine learning models, including those stored in BigQuery ML”, Tappen said.
“Because this functionality makes it easy for data scientists to share models and for app developers to use them, teams will become more empowered to turn data into real-time decisions,” Tappen added.
Pingback: สล็อต
Pingback: navigate to these guys
Pingback: web sunwin
Pingback: scam site: beware do not send money or do business with this site. 100% scam!
Pingback: about
Pingback: สล็อตวอเลท เว็บตรง ระบบการเงินแม่นยำ
Pingback: เว็บพนันออนไลน์เกาหลี
Pingback: oorbel Afrika
Pingback: tga168
Pingback: landing page